Back in 2013, Bryan Gick, Ian Wilson and myself published a textbook on “Articulatory Phonetics”. This book contained many assignments at the end of each chapter and in supplementary resources. After many years of using those assignments, Bryan, Ian, and many colleagues figured out that they needed some serious updating.
These updates have been completed, and are available here. The link includes recommended lab tools to use while teaching from this book, as well as links and external resources.
P.S. Don’t get too excited students – I’m not posting the answers here or anywhere else 😉
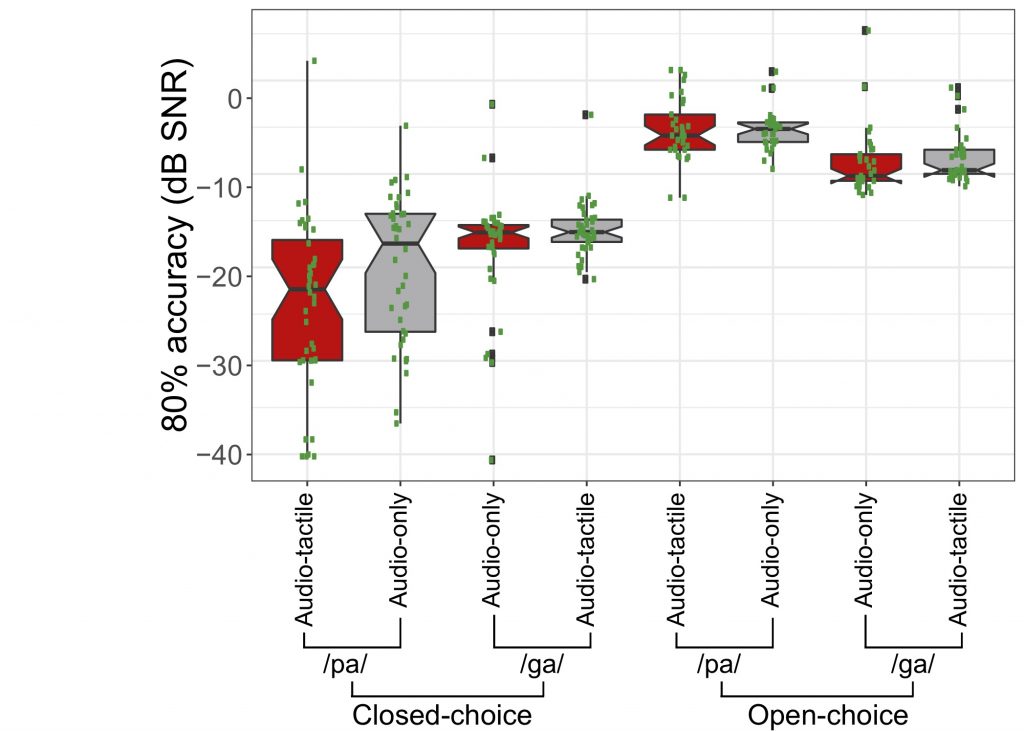
Jilcy Madappallimattam, Catherine Theys and I recently published an article demonstrating that aero-tactile stimuli does not enhance speech perception during open-choice experiments the way it does during two-way forced-choice experiments.
Abstract
Integration of auditory and aero-tactile information during speech perception has been documented during two-way closed-choice syllable classification tasks (Gick and Derrick, 2009), but not during an open-choice task using continuous speech perception (Derrick et al., 2016). This study was designed to compare audio-tactile integration during open-choice perception of individual syllables. In addition, this study aimed to compare the effects of place and manner of articulation. Thirty-four untrained participants identified syllables in both auditory-only and audio-tactile conditions in an open-choice paradigm. In addition, forty participants performed a closed-choice perception experiment to allow direct comparison between these two response-type paradigms. Adaptive staircases, as noted by Watson (1983). Were used to identify the signal-to-noise ratio for identification accuracy thresholds. The results showed no significant effect of air flow on syllable identification accuracy during the open-choice task, but found a bias towards voiceless identification of labials, and towards voiced identification of velars. Comparison of the open-choice results to those of the closed-choice task show a significant difference between both response types, with audio-tactile integration shown in the closed-choice task, but not in the open-choice task. These results suggest that aero-tactile enhancement of speech perception is dependent on response type demands.
Derrick, D., O’Beirne, G. A., De Rybel, T., Hay, J., and Fiasson, R. (2016). “Effects of aero-tactile stimuli on continuous speech perception,” Journal of the Acoustical Society of America, 140(4), 3225.
Gick, B., and Derrick, D. (2009). “Aero-tactile integration in speech perception,” Nature 462, 502–504.
Watson, A. B. (1983). “QUEST: A Bayesian adaptive psychometric method,” Perceptual Psychophysics, 33(2), 113–120.
Our three-dimensional printable ultrasound transducer stabilizer has been a huge success. It is in use here at the University of Canterbury, as well as the University of Michigan, Hiroshima University, University of California, Los Angeles, and soon at the University of British Columbia. (And it is available at Western Sydney University).
However, Phil Hoole at Ludwig Maximilian University of Munich figured out that the transducer stabilizer does *not* work with Children. He developed a solution to that problem, and I am making it available here. Within this zip file, there is a new probe holder. The base and clip-holder should be printed as is. Each remaining file needs to be scaled to 75% of their size and then printed. Each file marked with X2 needs to be printed *twice*.
I will put photos of this version of the probe-holder online once I have printed new copies and sewn all the pieces together sometime in October.
In 2013, I recorded 11 North American English speakers, each reading eight phrases with two flaps in two syllables (e.g “We have editor books”), and at 5 speech rates, from about 3 syllables/second to 7 syllables/second. Each recording included audio, ultrasound imaging of the tongue, and articulometry.
The dataset has taken a truly inordinate amount of time to label, transcribe (thank you Romain Fiasson), rotate, align ultrasound to audio, fit in shared time (what is known as a Procrustean fit), extract acoustic correlates, and clean from tokens that have recording or unfixable alignment errors.
It is, however, now 2019 and I have a cleaned dataset. I’ve uploaded the dataset, with data at each point of processing included, to an Open Science Framework website: I will, over the next few weeks, upload documentation on how I processed the data, as well as videos of the cleaned data showing ultrasound and EMA motion.
By September 1st, I plan on submitting a research article discussing the techniques used to build the dataset, as well as theoretically motivated subset of the articulatory to acoustic correlates within this dataset to a special issue of a journal whose name I will disclose should they accept the article for publication.
This research was funded by a Marsden Grant from New Zealand, “Saving energy vs. making yourself understood during speech production”. Thanks to Mark Tiede for writing the quaternion rotation tools needed to oriented EMA traces, and to Christian Kroos for teaching our group at Western Sydney Universiy how to implement them. Thanks to Michael Proctor for building filtering and sample repair tools for EMA traces. Thanks also to Wei-rong Chen for writing the palate estimation tool needed to replace erroneous palate traces. Special thanks to Scott Lloyd for his part in developing and building the ultrasound transducer holder prototype used in this research. Dedicated to the memory of Roman Fiasson, who completed most of the labelling and transcription for this project.
Katie Bicevskis, Bryan Gick, and I recently published “Visual-tactile Speech Perception and the Autism Quotient” in Frontiers in Communication: Language Sciences. In this article, we demonstrated that the more people self-describe as having autistic-spectrum traits, the more they tolerate a separation of time between air-flow hitting the skin and lip opening from a video of someone saying an ambiguous “ba” or “pa” when identifying the syllable they saw and felt, but did not hear.
First, in an earlier publication, we showed that visual-tactile speech integration depended on this alignment of lip opening and airflow, and that this is evidence of modality-neutral speech primitives. We use whatever information we have during speech perception regardless of whether we see, feel, or hear it.
Summary results from Bicevskis et al. (2016), as seen in Derrick et al. (2019).
This result is best illustrated with the image above. The image shows a kind of topographical map, where white represents the “mountaintop” of people saying the ambiguous audio-tactile syllable is a “pa”, and green represents the “valley” of people saying the ambiguous audio-tactile syllable is a “ba”. On the X-axis is the alignment of the onset of air-flow release and lip opening. On the Y-axis is the participants’ Autism-spectrum Quotient. Lower numbers represent people who describe themselves as having the least autistic-like traits; the most neurotypical. At the bottom of the scale, perceivers identify the ambiguous syllables as “pa” with as much as 70-75% likelihood when the air-flow arrived 100-150 milliseconds after lip opening – about when it would arrive if a speaker stood 30-45 cm away from the perceiver. Deviations led to steep dropoffs, where perceivers would identify the syllable as “pa” only 20-30% of the time if the air flow arrived 300 milliseconds before the lip opening. In contrast, at the top of the AQ scale, perceivers reported perceiving “pa” as little as only 5% more often when audio-tactile alignment was closer to that experienced in typical speech.
Interaction between audio-tactile alignment and Autism-spectrum Quotient.
These results are very similar what happens with people who are on the autism spectrum with audio-visual speech. Autists listen to speech with their ears more than they look with their eyes, showing a weak multisensory coherence during perceptual tasks (Happé and Frith, 2006). Our results suggest such weak coherence extends into the neutoryipcal population, and can be measured in tasks where the sensory modalities are well-balanced (which is easier to do in speech when audio is removed.)
References:
Bicevskis, K., Derrick, D., and Gick, B. (2016). Visual-tactile integration in speech perception: Evidence for modality neutral speech primitives. Journal of the Acoustical Society of America, 140(5):3531–3539
Derrick, D., Bicevskis, K., and Gick, B. (2019). Visual-tactile speech perception and the autism quotient. Frontiers in Communication – Language Sciences, 3(61):1–11
Derrick, D., Anderson, P., Gick, B., and Green, S. (2009). Characteristics of air puffs produced in English ‘pa’: Experiments and simulations. Journal of the Acoustical Society of America, 125(4):2272–2281
Happé, F., and Frith, U. (2006). The Weak Coherence Account: Detail-focused Cognitive Style in Autism Spectrum Disorders. Journal of Autism and Developmental Disorders, 36(1):5-25
I am going to be submitting an article entitled “Tri-modal Speech: Audio-Visual-Tactile integration in Speech Perception”, along with my co-authors Doreen Hansmann and Catherine Theys, within the month. The article was, in the end, a success, demonstrating that visual and tactile speech can, separately and jointly, enhance or interfere with accurate auditory syllable identification in two-way forced-choice experiments.
However, I am writing this short post to serve as a warning to anyone who wishes to combine visual, tactile, and auditory speech perception research into one experiment. Today’s technology makes that exceedingly difficult:
The three of us have collective experience with electroencephalography, magnetic resonance imaging, and with combining ultrasound imaging of the tongue with electromagnetic articulometry. These are complex tasks that require a great deal of skill and training to complete successfully. Yet this paper’s research was the most technically demanding and error-prone task we have ever encountered. The reason is that despite all of the video you see online today, modern computers do not easily allow for research-grade, synchronized video within experimental software. Due to today’s multi-core central processing, it was in fact easier to do such things a 15 years ago than it is now. The number and variety of computer bugs in the operating system, video and audio library codecs, and experimental software presentation libraries were utterly overwhelming.
We programmed this experiment in PsychoPy2, and after several rewrites and switching between a number of visual and audio codecs, we were forced to abandon the platform entirely due to unfixable intermittent crashes, and switch to MatLab and PsychToolBox. PsychToolBox also had several issues, but with several days of system debugging effort by Johnathan Wiltshire, programmer analyst at the University of Canterbury’s psychology department, these issues were at least resolvable. We cannot thank Johnathan enough! In addition, electrical issues with our own air flow system made completion of this research a daunting task, requiring a lot of help and repairs from Scott Lloyd of Electrical engineering. Scott did a lot of burdensome work for us, and we are grateful.
All told, I alone lost almost 100 working days to debugging and repair efforts during this experiment. We therefore recommend all those who follow up on this research make sure that they have collaborators with backgrounds in both engineering and information technology, work in labs with technical support, and have budgets and people who can and will build electrically robust equipment. We also recommend not just testing, debugging, and piloting experiments, but also the generation of automated iterative tools that can identify and allow the resolution of uncommon intermittent errors.
Your mental health depends on you following this advice.
Katie Bicevskis, Bryan Gick, and I just had “Visual-tactile Speech Perception and the Autism Quotient” – our reexamination and expansion our evidence for ecologically valid visual-tactile speech perception – accepted to Frontiers in Communications: Language Sciences. Right now only the abstract and introductory parts are online, but the whole article will be up soon. The major contribution of this article is that speech perceivers integrate air flow information during visual speech perception with greater reliance upon event-related accuracy the more they self-describe as neurotypical. This behaviour supports the Happé & Frith (2006) weak coherence account of Autism Spectrum Disorder. Put very simply, neurotypical people perceive whole events, but people with ASD perceive uni-sensory parts of events, often with greater detail than their neurotypical counterparts. This account partially explains how autists can have deficiencies in imagination and social skills, but also be extremely capable in other areas of inquiry. Previous models of ASD offered an explanation of disability, Happé and Frith offer an explanation of different ability.
I will be expanding on this discussion, with a plain English explanation of the results, once the article is fully published. For now, the article abstract is re-posted here:
“Multisensory information is integrated asymmetrically in speech perception: An audio signal can follow video by 240 milliseconds, but can precede video by only 60 ms, without disrupting the sense of synchronicity (Munhall et al., 1996). Similarly, air flow can follow either audio (Gick et al., 2010) or video (Bicevskis et al., 2016) by a much larger margin than it can precede either while remaining perceptually synchronous. These asymmetric windows of integration have been attributed to the physical properties of the signals; light travels faster than sound (Munhall et al., 1996), and sound travels faster than air flow (Gick et al., 2010). Perceptual windows of integration narrow during development (Hillock-Dunn and Wallace, 2012), but remain wider among people with autism (Wallace and Stevenson, 2014). Here we show that, even among neurotypical adult perceivers, visual-tactile windows of integration are wider and flatter the higher the participant’s Autism Quotient (AQ) (Baron-Cohen et al, 2001), a self-report screening test for Autism Spectrum Disorder (ASD). As ‘pa’ is produced with a tiny burst of aspiration (Derrick et al., 2009), we applied light and inaudible air puffs to participants’ necks while they watched silent videos of a person saying ‘ba’ or ‘pa’, with puffs presented both synchronously and at varying degrees of asynchrony relative to the recorded plosive release burst, which itself is time-aligned to visible lip opening. All syllables seen along with cutaneous air puffs were more likely to be perceived as ‘pa’. Syllables were perceived as ‘pa’ most often when the air puff occurred 50-100 ms after lip opening, with decaying probability as asynchrony increased. Integration was less dependent on time-alignment the higher the participant’s AQ. Perceivers integrate event-relevant tactile information in visual speech perception with greater reliance upon event-related accuracy the more they self-describe as neurotypical, supporting the Happé & Frith (2006) weak coherence account of ASD.”
There is a move afoot to have Kyklos retract “Do Linguistic Structures Affect Human Capital? The Case of Pronoun Drop”, by Prof Horst Feldmann of the University of Bath. This move is due to the fact that Horst Feldmann has used faulty statistical reasoning to make an argument that language structure is influencing economic wealth.
There are two main flaws: 1) The assumption that pro-drop languages are categorically different from non pro-drop languages in the first place. I have never seen a formal language model that suggest such a thing, though functional models likely allow for the possibility. (*Edit, a colleague privately told me of a formal model that does categorize pro-drop and non-pro-drop languages differently, but will not discuss further as they do not want to discuss the issue publicly.) 2) The assumption that languages are equally independent from each other. This is definitely wrong: It is obvious on many levels that English and French are, for instance, more similar than English and Japanese by both lineage and organization. Taking the second one into account might seriously alter any statistical model used to analyze the word language data used in Feldmann’s article.
However, I do not support this effort to demand Kyklos retract his article. It is much better to write an article that reexamines the data, using properly applied and properly reasoned statistical analysis, and rebuts Feldmann’s points if they are shown to be incorrect.
Once you go down the road of demanding that articles be retracted, not due to fraud or utter falsehood, but instead due to what you consider bad analysis, you’ve gone too far. I am morally gutted that any of my fellow linguists believe they can fight bad argumentation through suppression rather than effective counter-argument, and I repudiate such efforts.
Now, to be honest about myself and my limitations, I mostly ignore Economists when they talk about Linguistics in an Economics journal. Just as they might do were I to talk about Economics in a Linguistics journal. However, if any of my readers feels strongly enough to want to see the article retracted, here is my advice: It is much better to simply argue against the ideas, preferably using better statistical models, and write a great article while doing so. And if you do it well enough, you’ll really help your own career as well.
If your reanalysis shows Feldmann is thoroughly wrong, say so, and say it as forcefully as you want. But, be prepared to end up possibly agreeing with some of what Feldmann had to say. This outcome is possible as you don’t really know what a thorough analysis would show in advance of running the data. And if you think you can know in advance with certainty (rather than just strongly suspect) you might need to improve your scientific acumen.
Myself, Jenna Duerr, and Rachel Grace Kerr recently published an article documenting the main instrumental uses for Rivener, our mask-less air flow estimation and nasalance system. This device records audio and low-frequency pseudo-sound with microphones placed at the nose and mouth, separated by a baffle and placed in a Venturi tube to prevent that pseudo-sound from overloading the circuitry. The device can record all the aspects of hearing-impaired speech without interfering with the audio quality of the speaker or requiring physical contact with the system. If you want a detailed description of what the system can do, here is an unpublished “white paper” documenting the strengths and limitations of the system in detail.
Matthias has done amazing research into the relationship between native language and trombone play style. To quote him, Matthias’ “research explores the relationship of referential and non-referential forms of communication, such as language and (instrumental) music, respectively.”
Over the next year you can expect many more publications from Matthias, demonstrating the relationship between both acoustics and articulation of Tongan and English vowels and tongue position in steady-state trombone notes. Expect research into diffusion MRI to follow as Matthias will be adding brain imagery research to his repertoire.
Matthias is an excellent new researcher, and I expect great things from him throughout a long career. I am very proud to have had him as a PhD student, and to continue working and publishing with him.